主页 > imtoken恢复身份币不见了 > 肖震 北京大学《区块链技术与应用》06
肖震 北京大学《区块链技术与应用》06
19. 以太坊挖矿算法
20.以太坊挖矿难度调整
21.股权证明
19. 以太坊挖矿算法
区块链以挖矿为保障。
漏洞赏金
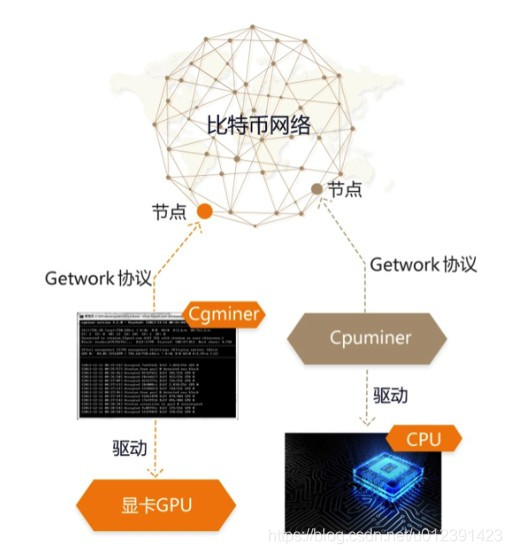
现在只能使用特定的显卡进行挖矿。 不公平。
中本聪提出,一个 CPU,一票。
后来很多币需要实现ASIC抗性
记忆力挖掘难题
ASIC和我们普通的显卡显存访问性能没有太大区别。
种子数组,第二个数是第一个数的哈希值,依次哈希。 比如求A,如果没有这个数组,就得依次计算,从头到A,如果不保存,就得从头计算,读到第二个。
莱特币,莱特币,基于 scrypt 的谜题
需要读取以太坊用什么算法,并且必须保存数组。 如果不保存,计算复杂度将显着增加。
只保存奇数和偶数时间记忆权衡
好处是矿工难以记忆
不好的部分是轻节点的内存困难
实际使用中,莱特币数组只有128K。
当时的目标不仅是抗ASIC还有抗GPU,但是128K太小对他们没有威胁,所以莱特币并没有通过这种方式达到目的。 早期这种slogan还是冷启动用的好。
莱特币的出块速度是两分半钟,其他基本和比特币一样。 ,
以太坊也是一个记忆难题,但设计完全不同。
16M缓存小数据集,由轻节点保存。计算方式和上面类似,从seed开始计算第一个值,依次取hash
1G数据集也叫DAG,矿工需要保存。
16M是由1G产生的。 这两个数据集有规律地增长。 比如现在的大数据集已经增加到2.5G。
DAG中的每个元素都是通过从small cacahe中读取256个值,然后计算一个元素来计算的。
解决这个难题需要使用大型数据集中的元素。
按照伪随机顺序,从大数据集中读取128个元素,根据区块头和nonce计算出一个初始hash,映射到大数据集的某个位置,读取,计算下一个位置读。 每次读取,都要读出相邻的元素。 循环64次,每次读2个,一共128个数。 最后计算一个hash,和我们的目标难度进行比较,看是否符合要求。 如果不是,请替换随机数。
ethash算法伪代码
Step1首先生成一个16M的缓存,每个元素是一个64字节的哈希值。
该函数是seed计算缓存的伪代码。
伪代码省略了原代码中对缓存元素的进一步处理,只展示了原理。即缓存的中间元素
元素是按顺序生成的,每个元素都是相对于前一个元素生成的。
每30000个区块重新生成种子(原种子的哈希值),使用新的种子生成
到一个新的缓存中。
缓存的初始大小为16M,每重新生成30000个block增加初始大小的1/128——
128K。
Step2 通过缓存生成大数据集中的元素。

这是通过缓存生成数据集中第 i 个元素的伪代码。
这个数据集叫做DAG,初始大小为1G,也是每30000个区块更新一次,同时增加初始大小
1/128——8M。
伪代码省略了大部分细节以显示原理。
首先通过缓存中的i%cache_size元素生成初始mix,因为可以将两个不同的dataset元素
可以对应同一个缓存中的元素。 为了保证每个初始的mix都是不同的,注意i也参与了hash
计算。
然后循环256次,每次get int from item根据当前mix值获取下一个要访问的缓存元素的下标,并使用这个缓存元素并mix。 通过 make_item 找到新的混合值。 注意,由于初始的mix值不同,所以访问缓存的顺序也不同。
最后返回mix的hash值,得到第i个数据集中的元素。
多次调用此函数以获得完整的数据集。
Step3 生成1G大数据集的过程
该函数通过不断调用前面介绍的calc_dataset_item函数依次生成dataset中的所有full size元素
Step4 矿工挖矿使用的函数和轻节点验证使用的函数
这个函数展示了ethash算法的谜题。 通过block header、nonce和DAG得到一个与target比较的值。 矿工和轻节点使用的实现方式不同。
伪代码省略了大部分细节以显示原理。 先通过header和nonce找到一个初始mix,然后进入64次循环,根据当前mix值找到要访问的diataset元素的下标,然后根据数据访问连续的两个值到这个下标。
(思考题:这两个值有关系吗?)
最后返回mix的hash值与targct进行比较。 注意,轻节点临时计算使用的数据集的元素,而矿工直接访问内存,即1G数据集必须存储在内存中,后面会分析其中的原因。
全尺寸的轻节点验证也是针对大数据集的。 不同的是,轻节点需要从缓存中生成大数据集中的这个元素。
Step5 矿工挖矿主循环
这是矿工挖矿函数的伪代码,为了说明原理也省略了一些细节。 full_ _size指数据集中的元素个数,数据集是缓存生成的DAG,header是区块头以太坊用什么算法,target是挖矿目标。 我们需要调整nonce,让hashimoto full的返回值小于等于target。 这里先随机初始化nonce,然后逐个尝试nonce,直到得到的值小于target。
下面是整个过程的伪代码,同时分析矿工需要保存整个数据集的原因。
红框内标注的代码表示当通过缓存生成数据集的元素时,元素在下一次使用的缓存中的位置是根据当前使用的缓存的元素的值来计算的,所以具体的访问顺序事前无法预测。 满足伪随机性。
由于矿工需要验证大量的nonce,如果每次都要从16M的缓存中重新生成,挖矿效率太低,这里会出现大量的重复计算:许多是重复的,并且可能在之前尝试其他随机数时使用过。 因此,矿工采用以空间换时间的策略来保存整个数据集。 由于轻节点只验证一个nonce,所以直接生成数据集中的元素来验证时使用即可。
到目前为止,以太坊挖矿仍然以GPU为主,ASIC很少,比莱特币更成功。
从工作量证明到股权证明。 还没有转换。 吓唬 ASIC 矿工。
权益证明,无挖矿。
以太坊使用预挖。 预挖,给早期开发者留分。
预售类似于众筹。 你在这个阶段买进,将来卖掉换钱。
事实证明,其中一半以上是预先开采的。 不管你怎么挖,关键是不要输在起跑线上。
20.以太坊挖矿难度调整
相当复杂。
基于代码。
Parent block,当前区块链的最后一个区块。 D0挖矿难度最低。
本来还担心大家不愿意转Proof of Stake,结果发现Proof of Stake有很多问题,还没有转过来。 于是,难度炸弹越来越难,挖矿也越来越难,但我们还是要继续挖下去。 尚未开发出新的共识机制。 后来,区块生成时间从 15 秒增加到 30 秒。 怎么做? 通过回滚300万个区块计算,H'为假区块号。
难度炸弹回调在拜占庭阶段进行。
BIP:比特币改进提案

减少区块奖励。 否则对大家不公平。 保持数量的稳定。
这方面众说纷纭,还是直接看代码比较好。
21.股权证明
权益证明
Twh=太瓦时 10^12
kwh=千瓦时10^3
比特币能源消耗增长。 它占世界能源消耗总量的0.31%。 挺大。 一笔交易要耗费一千度电。
以太坊占总能源消耗的 0.09%,每笔交易 67 千瓦时....
利润空间巨大。
说白了,挖矿的收益是由币量决定的。
虚拟挖矿
一部分货币留给开发者,一部分众筹。
小币种很容易枯竭。 山寨币杀婴扼杀在摇篮里
山寨币比特币以外的一种小货币
如果权益证明
攻击需要来自内部的资源。 不要想着从股市等外部市场进攻。
是一个闭环。 如果你想攻击股权证明,你需要花很多钱买这个币。 但是如果你买太多,价格就会上涨。
挖矿你持有的硬币越多,挖矿的难度就越小。
这也是有问题的。
投入的币将被锁定一段时间后被挖出。 存款证明。
早期基于权益证明的共识机制遇到的问题,双方都下注,没有利害关系
在以太坊早期使用。 Casper the friendly finality gadget (FFG)
引入验证者validator,交集margin。
每 100 个区块被开采为一个纪元。
进行两阶段提交
-准备消息
-提交信息
Casper规定每轮投票必须有三分之二以上的验证者通过才能通过。
现在减少到 50 个区块作为一个 epoch。 一次投票称为上一轮的准备消息和下一轮的提交消息。 只有连续两次投票达到 2/3 才有效。
验证者可以获得奖励。 乱投,押金将被没收。 不是作为可扣除的存款。
任期届满后,将有新的任期。 冷静期大家都觉得你没事,过段时间就可以拿回保证金了。
最终性由验证者投票决定。 矿工不能被推翻。
以太坊想一步步走向权益证明。
工作量证明相对成熟,而权益证明还不够成熟。
EOS 使用权益证明,不是 Casper 协议,而是 DPOS:委托权益证明
投票选出20个超级节点,他们将出块。 还在探索中。
挖矿将多余的电力转化为货币,带动经济发展……